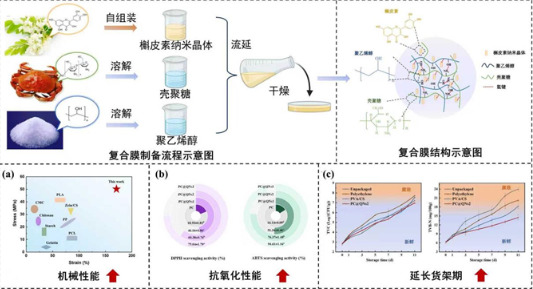
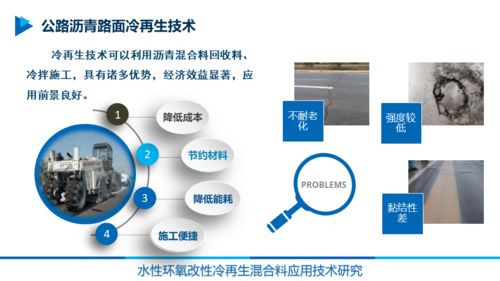
隨著人工智能技術的快速發展,大型語言模型(Large Language Models, LLMs)在多個領域展現出革命性的應用潛力。科研界迎來了首個基于單細胞生物學的超大規模語言模型,這一突破性進展在生物基材料技術研發領域開辟了全新路徑。該模型通過對超過1000萬個單細胞數據進行深度學習預訓練,顯著提升了生物分子機制的解析能力和材料功能的預測精度。
單細胞生物學技術使得研究者能夠在單個細胞水平上分析基因表達、蛋白質功能及代謝途徑,為理解生命系統的基本單元提供了前所未有的分辨率。傳統分析方法在處理海量單細胞數據時面臨計算復雜性和模式識別效率的挑戰。引入大型語言模型技術后,模型能夠從數百萬細胞的數據中學習細胞狀態、發育軌跡及環境響應模式,進而實現對生物分子網絡的精準建模。
在生物基材料研發中,該模型的應用具有深遠意義。生物基材料是指利用生物質資源(如微生物、植物或動物細胞)通過生物合成或轉化過程制備的新型材料,廣泛應用于醫療、能源和環保領域。傳統研發周期長、成本高,且依賴于試錯實驗。通過這一單細胞生物學大型語言模型,研究人員能夠:
- 預測細胞代謝路徑的最優改造方案,提高生物合成效率;
- 識別關鍵生物分子(如酶、多糖或蛋白質)的結構與功能關聯,指導高性能材料的理性設計;
- 模擬材料在復雜生物環境中的行為,加速生物相容性和功能穩定性的評估。
預訓練階段涵蓋的千萬級細胞數據來源于多個物種和組織類型,確保了模型的廣泛適用性和魯棒性。這一成就不僅推動了計算生物學與材料科學的交叉融合,也為可持續材料開發提供了智能化工具。隨著數據量和算法模型的進一步優化,單細胞生物學大型語言模型有望在個性化醫療、綠色制造及合成生物學中發揮更大作用。
首個單細胞生物學基礎的大型語言模型標志著生物技術研發進入智能化新階段。其在超千萬細胞數據上的預訓練成果,為生物基材料的技術創新注入了強大動力,有望加速實現從實驗室研究到產業應用的跨越。